Disclaimer:
This isn’t a guide, this post just outlines my approach at achieving a solution.
Our observability stack currently runs on a series of EC2 nodes. In an effort to improve scalability and management of the various components for Grafana we are moving to deploy this via Kubernetes
Stateful vs Stateless
One prominent question that I wanted to visit was the idea of managing Grafana resources statefully vs stateless. While I do prefer the stateless strategy here (managing alerts, dashboards other resources in code versus using storage, and because everything is in code we only need to worry about storage for our metrics/logging data), I believe the goal for this stack down the road is to enable teams to set their own alerting and dashboards. With that, it would make more sense for teams to interact with the UI to make these changes.
Planning work
- Set up a testing environment for deploying and testing changes quick
- Deploy our stack on k8s (no data involved)
- Grafana OnCall
- Grafana Alerting
- Grafana Server
- VictoriaMetrics Operator
- Loki
- Mimir
- Grafana OnCall
- Migrate less-involved services to k8s first
-
Deploy and configure chart for k8s
-
Test data storage, backups and restore from backups
-
Migration from Prometheus alerts to Grafana alerts
-
Additional services to integrate in the future
- Synthetic testing w/ K6
-
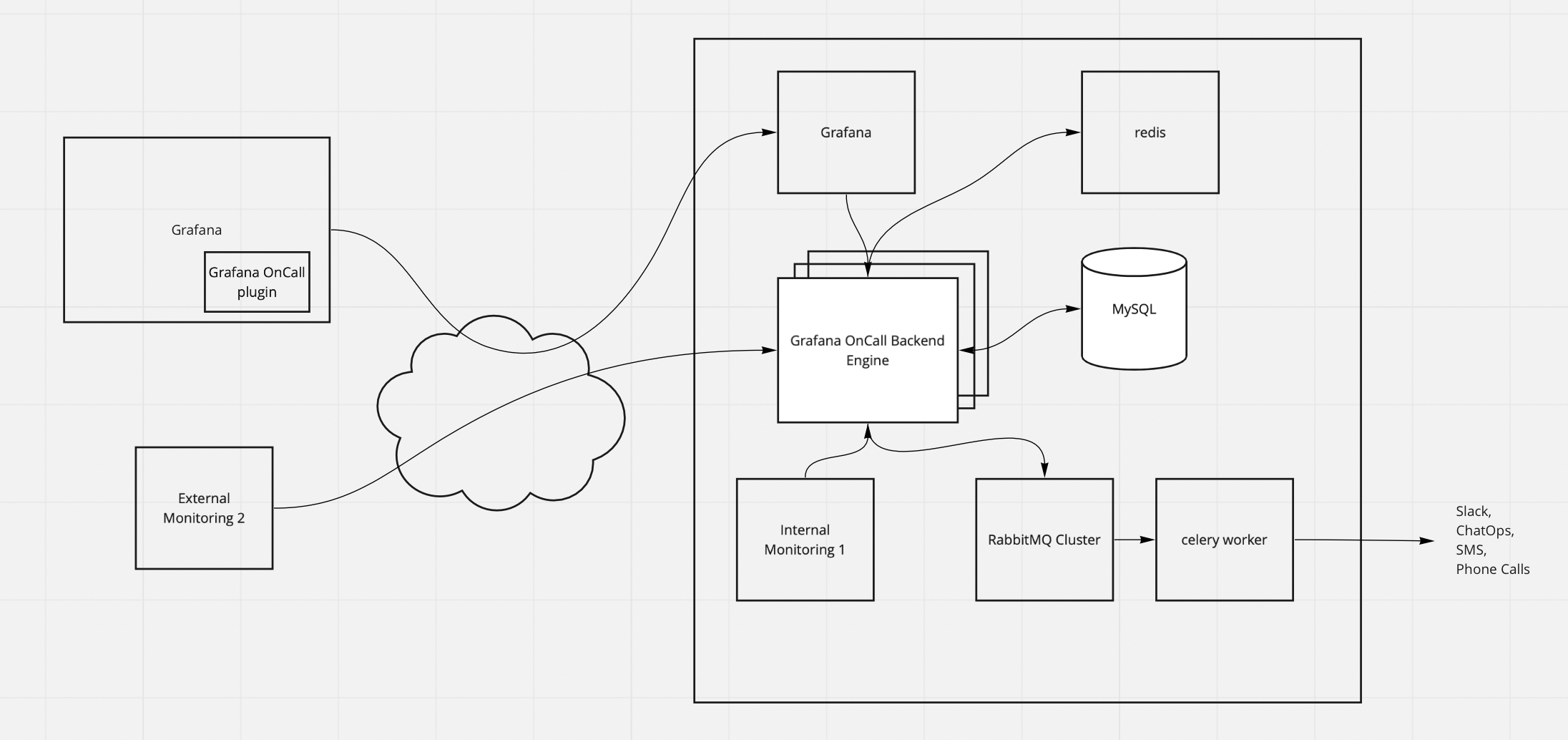
Migrating Grafana and Oncall
The first services we decided to cut over was grafana and oncall. The current setup runs the services on ec2 nodes with a local sqlite3 database.
- Migrate data over to Postgres
- Test existing setup on postgres
- Migrate to helm chart
Optional:
- Update
- Enable feature toggle
externalServiceAccounts
Working with postgres
In order to verify and check the data I was working with, I ran a postgres test pod, with the appropriate db information mounted to the environment and connected via:
psql postgres://$DATABASE_USER:$DATABASE_PASSWORD@$DATABASE_HOST:$DATABASE_PORT/$DATABASE_NAME
Migrating Grafana
There were a few references online for migrating Grafana from an existing sqlitedb. The general consensus was the following:
- Have a fresh instance of grafana generate schemas for the database
- Wipe data in tables and re-import via a tool such as
pgloader
By following this approach, I was able to import Grafana database to postgres fairly seemlessly using the following main.load:
load database
from sqlite://grafana.db
into ${DB_CONNECTION_STRING}?sslmode=allow
with data only, truncate, disable triggers, reset sequences, prefetch rows=1000
set work_mem to '2048 MB', maintenance_work_mem to '4096 MB'
Following this, I updated the grafana configuration to reference the new postgres secrets:
[database]
type = postgres
host = ${GRAFANA_POSTGRES_HOST}:${GRAFANA_POSTGRES_PORT}
name = ${GRAFANA_POSTGRES_DB_NAME}
user = ${GRAFANA_POSTGRES_USER}
password = ${GRAFANA_POSTGRES_PASSWORD}
ssl_mode = require
That’s it! Time to move on to grafana-oncall. Surely, this should go similarly … right?
Wrong.
The default conversion from bigint to interval treats the value as a measure of seconds when in reality it is a measure of microseconds. This causes the values in this field to bubble up to extremely large intervals.
Converting between response_time stored as bigint on sqlite3 to interval:
CREATE TABLE EMPLOYEE (
empId INTEGER PRIMARY KEY,
name TEXT NOT NULL,
dept TEXT NOT NULL,
time INTERVAL NOT NULL
);
-- alter table the_table
-- alter amount type bigint using (amount * 100)::bigint;
INSERT INTO EMPLOYEE VALUES (0001, 'Clark', 'Sales', '2501:00:00'::INTERVAL);
SELECT EXTRACT(EPOCH FROM time) from EMPLOYEE;
ALTER TABLE EMPLOYEE
ALTER time type INTERVAL using EXTRACT(EPOCH FROM time) * '1 microsecond'::INTERVAL;
SELECT time from EMPLOYEE;
SELECT EXTRACT(EPOCH FROM time) from EMPLOYEE;
Placing this on hold for now as we determined our current k8s setup isnt as reliable as we need it to be, especially for this critical service stack. We will need to invest some time in building up a resilient and reliable cluster before moving forward with moving the migration.